In the simplest sense, naming conventions serve as labels for digital files. These conventions should lend themselves to be applied in a systematic and consistent manner. Our current practice is to defined specific naming conventions at a project level. Such schema should be determined prior to the start of the digital capture process and guidelines provided to the scanning operator. (an example guideline is supplied at the end of this page)
From a project management perspective, the file naming convention is an important consideration in planning the digital creation process. The ease of use or practicality of the naming convention impacts compilers of digital objects on a daily basis from scanning operators during the image capture process to encoders during text markup work. As a general rule of thumb, the simpler a naming scheme is to form, the easier it is to communicate, manage and maintain. During the product development stage, the file naming convention serves a dual purpose not only to uniquely identify digital files but as an aid for manually tracking the various files until the complete object is ready for ingest into the repository.
There are a number of commonly accepted practices in forming file naming schemas. These can be applied across most projects and are condensed as follows: .
Required:
-
All filenames should be unique
-
The filenaming schema should provide a logical sequence that can be easily identified and reproduced
-
A uniform naming convention should be applied within a particular collection or project
-
Follow good practices in selecting characters for creating file names. These include:
-
no blank spaces,
-
no special symbol characters - that is any characters typically used in programming language such as percent signs (%), question marks (?),etc
-
consistently apply case (e.g. all small or “camel” format), and
-
the use of leading zeros for numeric driven schema
-
Take into account the maximum number of items to be scanned
-
Do not use an overly complex or lengthy naming scheme that is susceptible to human error during manual input.
Recommended
An important consideration in defining file naming schema is the multipart object. A digital representation of a physical object may actually be composed of multiple files. For instance a book containing hundreds of pages where each digital file corresponds to one-side of a physical page and only when all files are taken as a group comprises the entire book. In this case, the book (multiple pages images) represents one record in the data repository system.
image files + metadata = 1 record (DSpace item)
For the purposes of managing the digital creation process, which includes a level of manual tracking, a naming convention that provides some level of structural information is very helpful if not outright necessary. This is especially true in multipart objects to ensure pagination is maintained for accurate display and navigation in the final presentation.
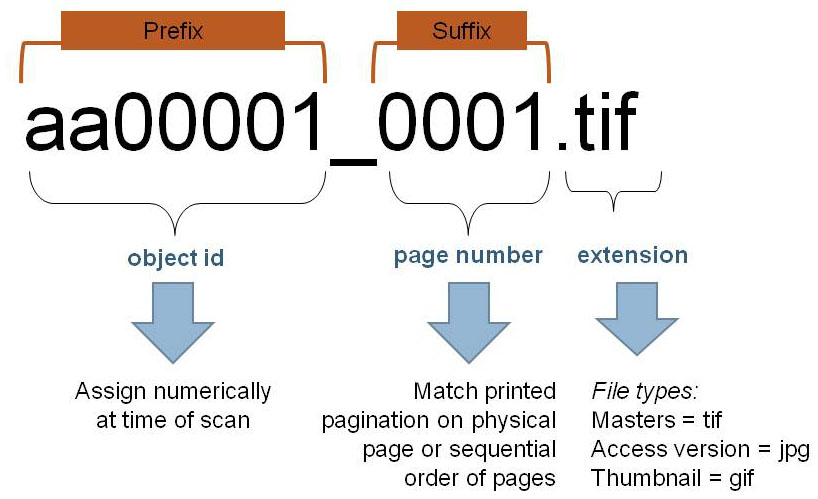
Therefore digital file names can be setup to be composed of two parts: 1) a prefix number to represent the object level and 2) combined with a suffix number to represent a particular page and its order within that object. This method captures the basic structure of an object where the roll up of individual files is apparent from the file name. This method greatly aids in organizing the structure of digital files into one seamless object and impacts downstream workflow digitization processes, such as text mark.
Figure: Filename breakout
-
For multipart objects, it is recommended to use a two-part naming convention that tracks the page sequence as well as the object level.
-
The complete digital file name is composed of two parts: prefix and suffix. The prefix represent the object identifier and the suffix corresponds to page order, and in the case of printed texts, should match the printed pagination on the physical page.
Optional practice
Use of codes to represent department or collection.
Examples:
wrcXXXXX_001.tiff Woodson Research Center
ssm00001a001.wav Shepherd School of Music
Viewing data from a holistic approach, having individual files with a component of their identifiers to denote sub communities or collections can aid in the overall management of files particularly when multiple projects are being worked simultaneously or in collaborative projects with multiple partner institutions. However, this practice does add on to the overall length of filenames and for stand-alone projects may be more cumbersome than is beneficial.
File extensions
Naming conventions should be applied consistently to an individual digital object regardless to file format. In this manner masters and derivatives that represent the same physical object will both have the same identifier but are distinguished by the appropriate type of file extension. In the below example only the extension has changed; identifiers remain constant per digital representation.
Example: Different digital versions of same page image
wrcXXXXX_001.tiff Master
wrcXXXXX_001.jpg Derivative
--same identifier, different extension
Permanent identifiers
The ultimate (or final) digital identifier will be assigned automatically at the time of ingest to the digital repository. This assignment occurs at the end of the digitization process. This final identifier is the permanent and persistent URL for the completed digital object. DSpace uses the handle system <www.handle.net/> for assigning ids.
Example
dc.title : Map of the American Hemisphere, 1823
dc.identifier.digital : aa00033
dc.identifier.uri : http://hdl.handle.net/1911/9254
Sources:
Comments (0)
You don't have permission to comment on this page.